James Tait
今日のデータドリブンな投資環境において、データの質、入手可能性、そして具体性が、戦略の成否を左右します。しかし投資の専門家は、しばしば制約に直面します。過去のデータセットは新たなリスクを捉えられない可能性があり、オルタナティブデータは不完全であったり、非常に高額であったりします。さらに、オープンソースのモデルやデータセットは、主要な市場や英語コンテンツに偏っています。
企業がより適応性が高く、先を見据えたツールを求める中で、特に生成AI(GenAI)から得られる合成データは、戦略的資産として浮上しています。これにより、市場シナリオのシミュレーション、機械学習モデルの訓練、投資戦略のバックテストなど、新たな手段が提供されます。本記事では、生成AIによる合成データが、資産相関のシミュレーションからセンチメントモデルの強化に至るまで、どのように投資ワークフローを再構築しているのか、そしてその有用性や限界を評価するために実務に携わる者が知っておくべきことを探ります。
では、合成データとは何なのか、生成AIモデルによってどのように生成されるのか、そしてなぜ投資分野での活用において重要性を増しているのでしょうか。
2つの一般的な課題を考えてみましょう。1つ目は、さまざまな市場局面におけるパフォーマンス最適化を目指すポートフォリオマネージャーが、まだ起きていない「もしも」のシナリオを考慮できない過去のデータによって制約されるケースです。もう1つは、小型株に関するドイツ語ニュースのセンチメントを監視するデータサイエンティストが、利用可能なデータセットの多くが英語で、大型株に焦点を当てているため、カバレッジと関連性の両方が制限されるケースです。どちらのケースにおいても、合成データは実用的な解決策を提供します。
生成AIによる合成データを際立たせるもの ― そしてなぜ今それが重要なのか
合成データとは、実世界のデータが持つ統計的特性を再現するよう人工的に生成されたデータセットを指します。この概念自体は新しいものではなく、モンテカルロ・シミュレーションやブートストラップのような手法は、長らく金融分析を支えてきました。しかし変化したのは、その生成方法です。
生成AIとは、テキスト、表形式データ、画像、時系列など、複数のデータ形式にわたって高忠実度の合成データを生成できる深層学習モデルの一群を指します。従来の手法とは異なり、生成AIモデルは実世界の複雑な分布をデータから直接学習し、基礎となる生成過程についての厳格な仮定を置く必要がありません。 この能力は、特に実データが乏しい、複雑、不完全、あるいはコスト、言語、規制によって制約されている分野において、投資運用に強力な活用方法をもたらします。
一般的な生成AIモデル
生成AIモデルにはさまざまな種類があります。変分オートエンコーダー(VAEs)、敵対的生成ネットワーク(GANs)、拡散モデル(diffusion-based models)、および大規模言語モデル(LLMs)が最も一般的です。各モデルはニューラルネットワークアーキテクチャを用いて構築されていますが、そのサイズや複雑さは異なります。これらの手法はすでに業界内のデータ中心のワークフローを強化する可能性を示しています。例えば、VAEsはオプション取引の改善のために合成のボラティリティサーフェスを作成するために使われています(Bergeron et al., 2021)。GANsはポートフォリオ最適化やリスク管理に有用であることが示されています(Zhu, Mariani and Li, 2020; Cont et al., 2023)。拡散モデルは、さまざまな市場局面下での資産リターンの相関行列をシミュレートするのに役立つことが証明されています(Kubiak et al., 2024)。そしてLLMsは市場シミュレーションに有用であることが示されています(Li et al., 2024)。
表1. 合成データ生成のアプローチ
|
手法
|
生成するデータの種類
|
応用例
|
生成型か?
|
|
モンテカルロ (Monte Carlo)
|
時系列、表形式データ
|
ポートフォリオ最適化、リスク管理
|
いいえ
|
|
コピュラ関数(Copula-based functions)
|
時系列、表形式データ
|
クレジットリスク分析、資産相関モデリング
|
いいえ
|
|
自己回帰モデル(Autoregressive models)
|
時系列データ
|
ボラティリティ予測、資産リターンのシミュレーション
|
いいえ
|
|
ブートストラップ(Bootstrapping)
|
時系列、表形式、テキストデータ
|
信頼区間の作成、ストレステスト
|
いいえ
|
|
変分オートエンコーダー(Variational Autoencoders)
|
表形式、時系列、音声、画像
|
ボラティリティサーフェスのシミュレーション
|
はい
|
|
敵対的生成ネットワーク(Generative Adversarial Networks)
|
表形式、時系列、音声、画像
|
ポートフォリオ最適化、リスク管理、モデル訓練
|
はい
|
|
拡散モデル(Diffusion models)
|
表形式、時系列、音声、画像
|
相関モデリング、ポートフォリオ最適化
|
はい
|
|
大規模言語モデル(Large language models)
|
テキスト、表形式、画像、音声
|
センチメント分析、市場シミュレーション
|
はい
|
合成データの質の評価
合成データは現実的で実データの統計的特性と一致しているべきです。既存の評価方法は、大きく定量的評価と定性的評価の2つに分類されます。
定性的評価は、実データと合成データセットの比較を可視化する方法です。例として、分布の可視化、変数のペアごとの散布図の比較、時系列の軌跡や相関行列の比較があります。例えば、バリュー・アット・リスク推定のための資産リターンをシミュレートするために訓練されたGANモデルは、分布の裾の重さ(ヘビーテール)を正しく再現できなければなりません。また、異なる市場局面下で合成の相関行列を生成するために訓練された拡散モデルは、資産の共動きを適切に捉える必要があります。
定量的評価には、コルモゴロフースミルノフ(Kolmogorov-Smirnov)検定、Population Stability Index(PSI)、JSダイバージェンス(Jensen-Shannon Divergence)など、分布の比較を行う統計的検定が含まれます。これらの検定は、2つの分布の類似度を示す統計量を出力します。例えば、コルモゴロフースミルノフ検定はp値を出力し、これが0.05未満であれば、2つの分布は有意に異なると判断されます。これは可視化に比べ、2つの分布の類似度をより具体的に測る方法となります。
別の手法として「train-on-synthetic, test-on-real(TSTR)」があります。これは合成データでモデルを訓練し、実データでテストを行う方法です。このモデルの性能を、実データで学習・テストしたモデルと比較します。もし合成データが実データの特性を正しく再現していれば、両者の性能は類似するはずです。
実践例:生成AI合成データによる金融センチメント分析の強化
これを実践するために、私は小規模なオープンソースLLMであるQwen3-0.6Bを、金融関連の見出しやソーシャルメディアコンテンツの公開データセットであるFiQA-SA[1]を用いて金融センチメント分析向けにファインチューニングしました。このデータセットは822件の学習例で構成されており、大半の文が「Positive(肯定的)」または「Negative(否定的)」のセンチメントに分類されています。
次に、GPT-4oを使って800件の合成学習例を生成しました。GPT-4oによって生成された合成データセットは、元の学習データよりも多様性が高く、より多くの企業とセンチメントをカバーしています(図1)。 学習データの多様性が増すことで、LLMはテキストコンテンツからセンチメントを識別するための学習例をより多く得られ、未知のデータに対するモデル性能の向上が期待されます。
図1. センチメントクラスの分布:実データ(左)、合成データ(右)、実データと合成データを組み合わせた増強学習データセット(中央)
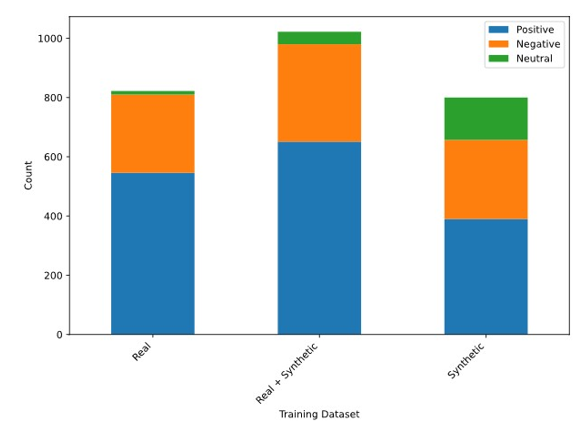
表2:実データおよび合成学習データセットからの例文
|
文
|
分類
|
データ種別
|
|
Weirの不振がFTSEを最高値から下落させる。
|
ネガティブ
|
実データ
|
|
アストラゼネカが主要な新肺がん治療薬のFDA承認を獲得。
|
ポジティブ
|
実データ
|
|
シェルとBGの株主は1月末に合意案に投票予定
|
ニュートラル
|
実データ
|
|
テスラの四半期報告で車両納入が15%増加。
|
ポジティブ
|
合成データ
|
|
ペプシコは最近の製品リコールに関する記者会見を開催予定。
|
ニュートラル
|
合成データ
|
|
ホーム・デポのCEOが内部の論争の中で突然辞任。
|
ネガティブ
|
合成データ
|
同じ学習手順で実データと合成データの組み合わせで2つ目のモデルをファインチューニングしたところ、検証データセットでのF1スコアが約10ポイント向上し(表3)、テストデータセットでの最終F1スコアは82.37%となりました。
表3: FiQA-SA検証データセットにおけるモデル性能
|
モデル
|
重み付きF1スコア
|
|
モデル1(実データのみ)
|
75.29%
|
|
モデル2(実データ+合成データ)
|
85.17%
|
合成データの割合を増やしすぎると、悪影響があることが分かりました。最適な結果を得るには、合成データの割合が多すぎず少なすぎない「ゴールディロックスゾーン」が存在します。
万能薬ではないが、価値あるツール
合成データは実データの代替ではありませんが、試してみる価値はあります。手法を選び、合成データの品質を評価し、合成データの使用有無や使用割合を変化させてワークフローを比較するA/Bテストをサンドボックス環境で実施してください。その結果に驚くかもしれません。
[1] このデータセットは以下のリンクからダウンロード可能です:
https://huggingface.co/datasets/TheFinAI/fiqa-sentiment-classification
この投稿が気に入られたらEnterprising Investorのご購読をお願い致します。
執筆者
James Tait
(翻訳者:村上みさき, CFA)
英文オリジナル記事はこちら
https://blogs.cfainstitute.org/investor/2025/07/31/how-genai-powered-synthetic-data-is-reshaping-investment-workflows/#_ftn1
注) 当記事はCFA協会(CFA Institute)のブログ記事を日本CFA協会が翻訳したものです。日本語版および英語版で内容に相違が生じている場合には、英語版の内容が優先します。記事内容は執筆者の個人的見解であり、投資助言を意図するものではありません。
また、必ずしもCFA協会または執筆者の雇用者の見方を反映しているわけではありません。